Abstract
Generalizing deep learning models to unknown target domain distribution with low latency has motivated research into test-time training/adaptation (TTT/TTA). Existing approaches often focus on improving test-time training performance under well-curated target domain data. As figured out in this work, many state-of-the-art methods fail to maintain the performance when the target domain is contaminated with strong out-of-distribution (OOD) data, a.k.a. open-world test-time training (OWTTT). The failure is mainly due to the inability to distinguish strong OOD samples from regular weak OOD samples. To improve the robustness of OWTTT we first develop an adaptive strong OOD pruning which improves the efficacy of the self-training TTT method. We further propose a way to dynamically expand the prototypes to represent strong OOD samples for an improved weak/strong OOD data separation. Finally, we regularize self-training with distribution alignment and the combination yields the state-of-the-art performance on 5 OWTTT benchmarks.
Motivation
Despite many efforts into developing stable and robust TTT methods under a more realistic open-world environment, in this work, we delve into an overlooked, but very commonly seen open-world scenario where the target domain may contain testing data drawn from a significantly different distribution, e.g. different semantic classes than source domain, or simply random noise. We refer to the above testing data as strong out-of-distribution (strong OOD) data, as opposed to distribution-shifted testing data, e.g. common corruptions, which are referred to as weak OOD data in this work. The ignorance of this realistic setting by existing works, thus, drives us to explore improving the robustness of open-world test-time training (OWTTT) where testing data is contaminated with strong OOD samples.
As shown in the figure below, we first empirically evaluate existing TTT methods and reveal that TTT methods through self-training and distribution alignment would all suffer substantially subject to strong OOD samples. These results suggest applying existing TTT techniques fails to achieve safe test-time training in the open-world.

Overview

Results on Benchmark Datasets
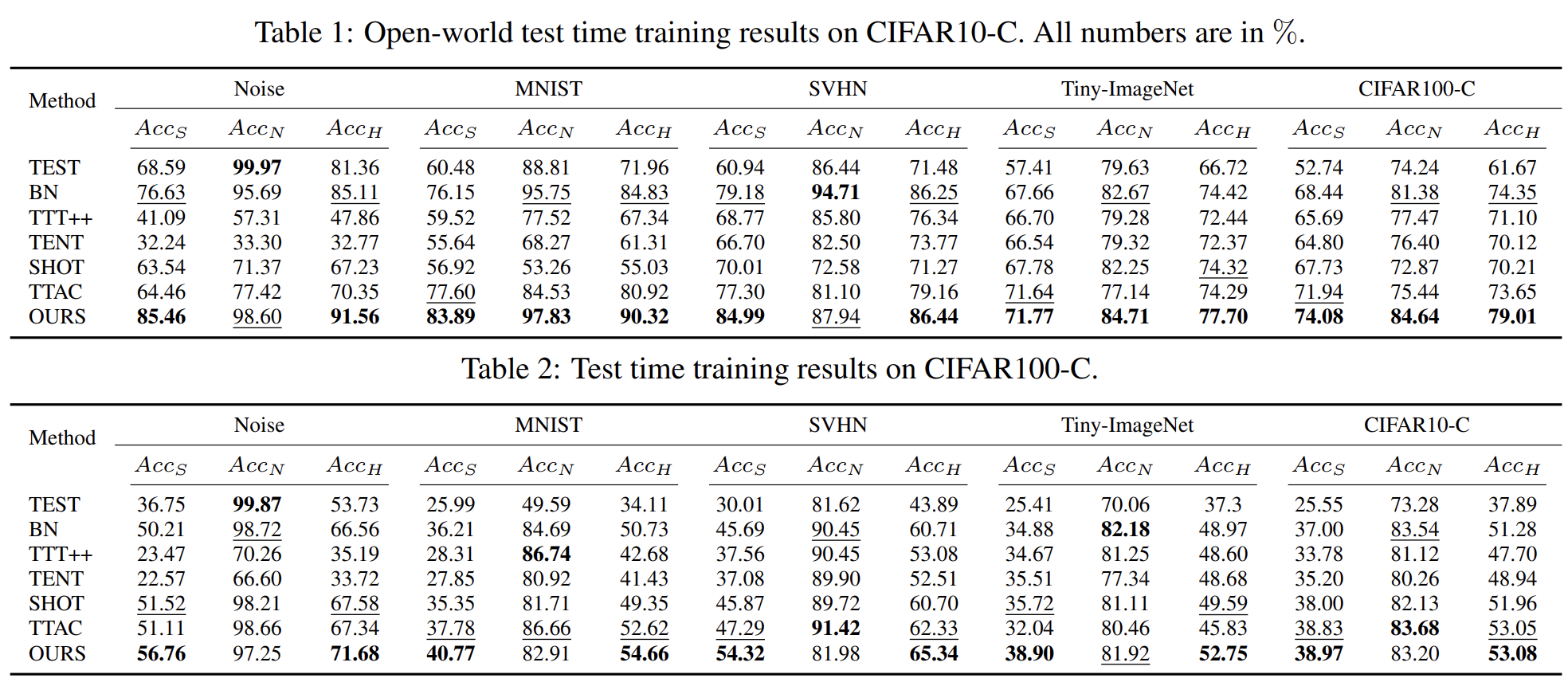
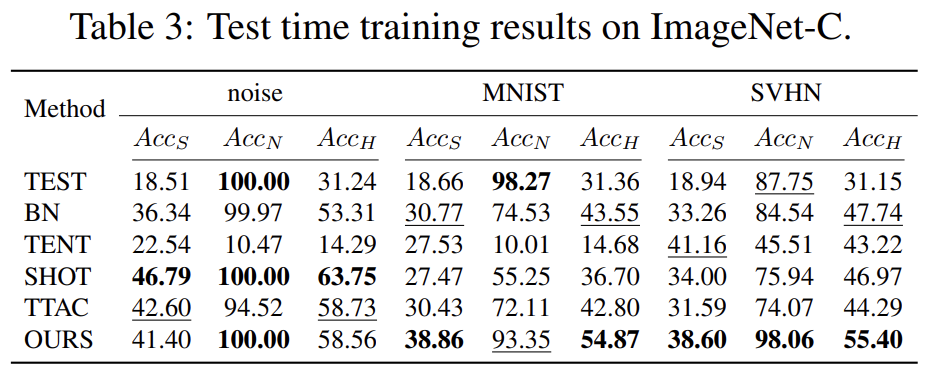

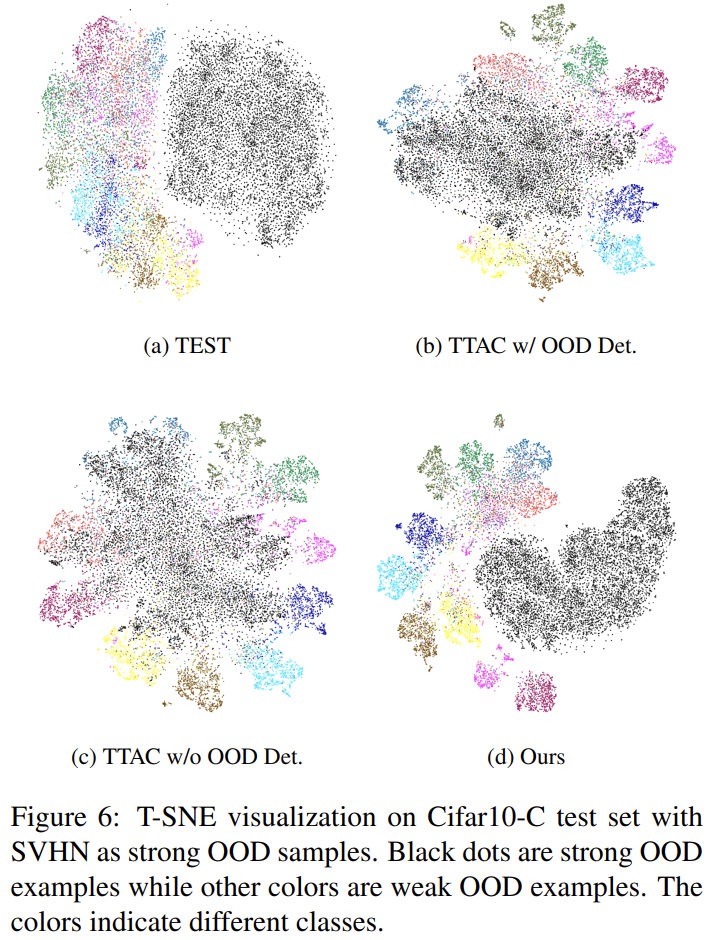
Ablation Study & Additional Analysis